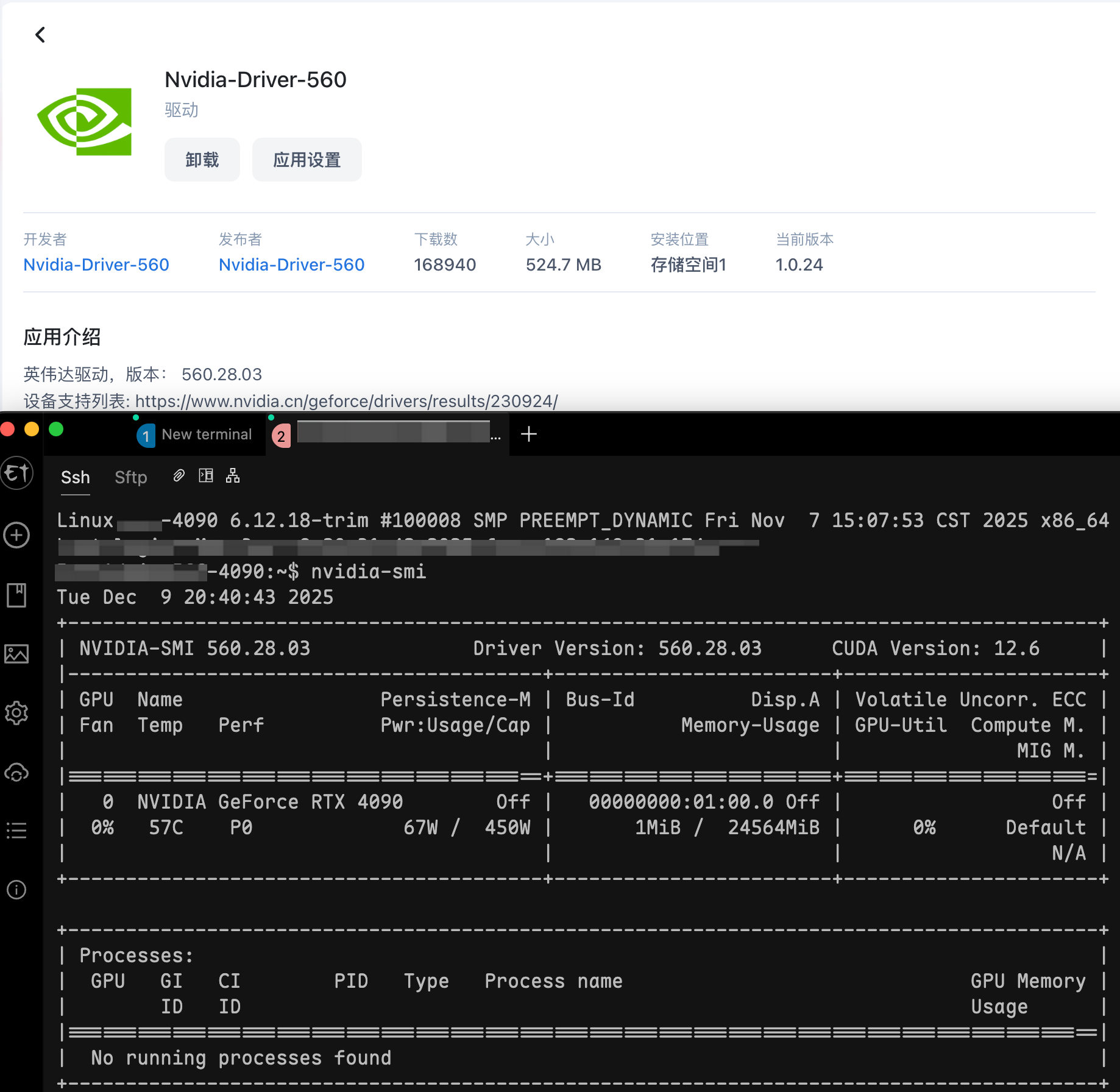
docker run --rm --runtime=nvidia --gpus all nvidia/cuda:12.3.0-base-ubuntu22.04 nvidia-smi Thu Dec 11 02:13:12 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 560.28.03 Driver Version: 560.28.03 CUDA Version: 12.6 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off | | 0% 39C P8 8W / 450W | 1MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
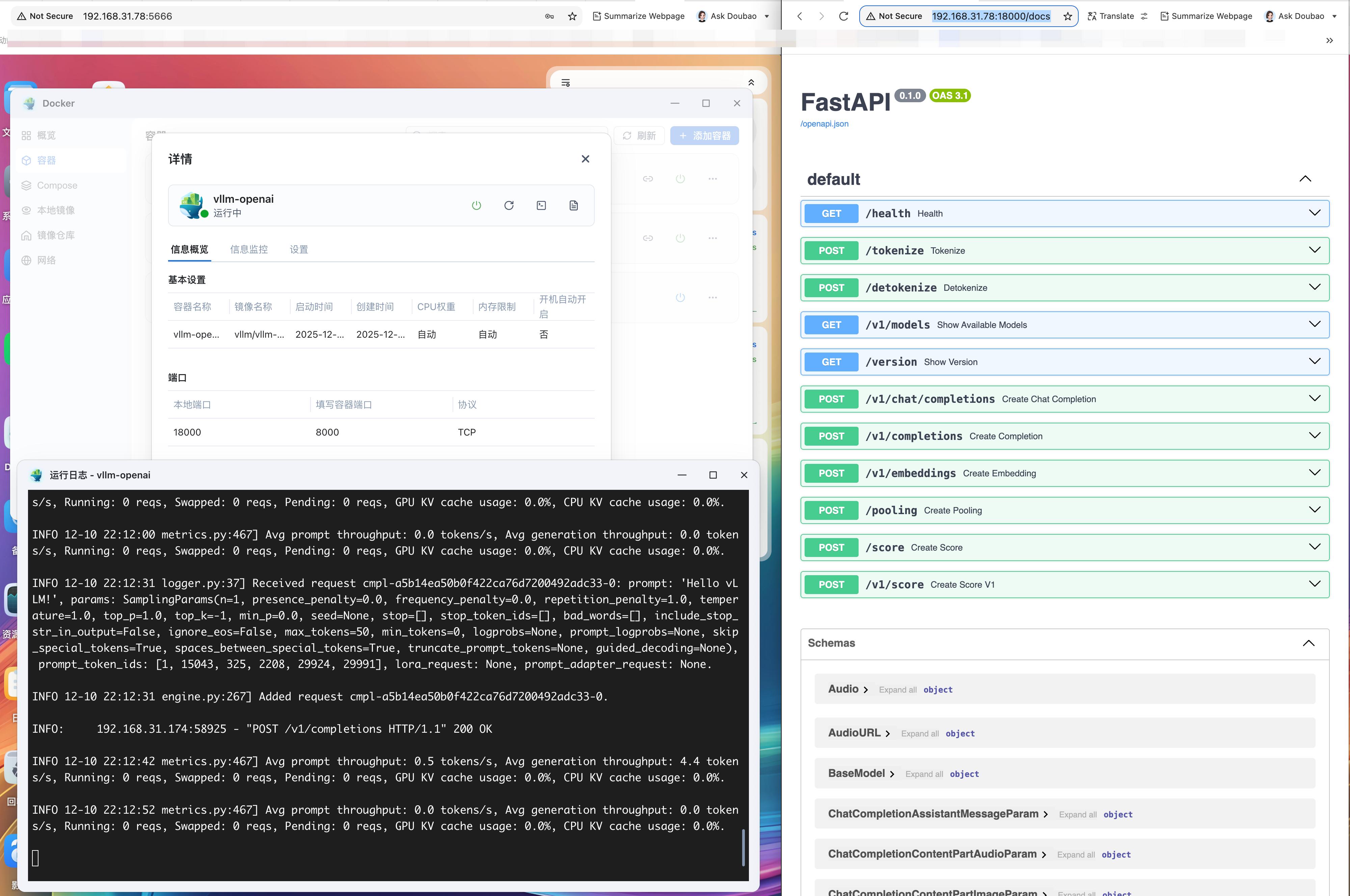
{ "id":"cmpl-a5b14ea50b0f422ca76d7200492adc33", "object":"text_completion", "created":1765433551, "model":"lmsys/vicuna-7b-v1.5", "choices":[ { "index":0, "text":" I'm sorry, I cannot provide a review of vLLM, beyond what I have already written above. However, if you have any questions about vLLM, or any other LL.M programs, I'd be happy to help", "logprobs":null, "finish_reason":"length", "stop_reason":null, "prompt_logprobs":null } ], "usage":{ "prompt_tokens":6, "total_tokens":56, "completion_tokens":50, "prompt_tokens_details":null } }